Par Yann CHOVORY, Ingénieur en IA appliquée à la criminalistique (Institut Génétique Nantes Atlantique – IGNA). Sur une scène de crime, chaque minute compte. Entre l’identification d’un suspect en fuite, la prévention de nouveaux délits et les contraintes temporelles de l’enquête, les enquêteurs sont engagés dans une véritable course contre la montre. Traces digitales, résidus de tir, traces biologiques, vidéosurveillance, données numériques… Autant d’indices qui doivent être collectés et analysés rapidement, sous peine de voir une affaire s’effondrer faute de preuves exploitables à temps. Pourtant, submergés par la masse croissante de données, les laboratoires de forensiques peinent à suivre le rythme.
Analyser les preuves avec rapidité et précision
Dans ce contexte, l’intelligence artificielle (IA) s’impose comme un accélérateur indispensable. Capable de traiter en quelques heures des volumes d’informations qui prendraient des semaines à analyser manuellement, elle optimise l’exploitation des indices en accélérant leur tri et en détectant des liens imperceptibles à l’œil humain. Plus qu’un simple gain de temps, elle permet aussi d’améliorer la pertinence des investigations : croiser rapidement des bases de données, repérer des motifs cachés dans des schémas d’appels téléphoniques, comparer des fragments d’ADN avec une précision inégalée. L’IA agit ainsi comme un analyste virtuel infatigable, réduisant le risque d’erreurs humaines et offrant de nouvelles perspectives aux experts en forensiques.
Mais cette révolution technologique ne se fait pas sans heurts. Entre scepticisme institutionnel et résistances opérationnelles, son intégration dans les pratiques d’enquête reste un défi. Mon parcours professionnel, marqué par une quête obstinée d’intégrer l’IA à la police scientifique, illustre cette transformation – et les obstacles qu’elle rencontre. De bioinformaticien marginalisé à responsable de projets IA à l’IGNA, j’ai pu observer de l’intérieur comment cette discipline, longtemps fondée sur des méthodes traditionnelles, s’adapte, parfois à marche forcée, à l’ère du big data.
Le risque d’erreur humaine est réduit et la fiabilité des identifications augmentée
Des exemples concrets : l’IA à l’œuvre de la scène de crime au laboratoire
L’IA investit déjà plusieurs domaines de la criminalistique, avec des résultats prometteurs. Par exemple, les systèmes de reconnaissance d’empreintes digitales AFIS (Automated Fingerprint Identification System ou Système d’identification automatique par empreintes digitales) intègrent désormais des composantes d’apprentissage automatique pour améliorer la correspondance des empreintes latentes. Le risque d’erreur humaine est réduit et la fiabilité des identifications augmentée [1]. De même, en balistique, des algorithmes de vision par ordinateur comparent automatiquement les stries d’un projectile aux empreintes d’armes connues, accélérant le travail d’un expert en identification d’armes à feu. Nous voyons également apparaître des outils pour interpréter les traces de sang sur une scène : des modèles de machine learning1 peuvent aider à reconstituer la trajectoire de gouttelettes de sang et donc la dynamique d’une agression et d’un évènement sanglant [2]. Ces exemples illustrent comment l’IA s’intègre dans la boîte à outils de l’expert criminalistique, de l’analyse d’images de scène de crime à la reconnaissance de motifs complexes.
Mais c’est sans doute en génétique forensique que l’IA suscite actuellement le plus d’espoirs. Les laboratoires d’analyse ADN traitent des milliers de profils génétiques et d’échantillons, avec des délais qui peuvent être critiques. L’IA offre un gain de temps considérable et une précision accrue. Dans le cadre de mes recherches, j’ai contribué au développement d’une IA interne capable d’interpréter 86 profils génétiques en seulement trois minutes [3], un progrès majeur lorsque l’analyse d’un profil complexe peut prendre plusieurs heures. Depuis 2024, elle traite en autonomie les profils simples, tandis que les profils génétiques complexes sont automatiquement orientés vers un expert humain, garantissant ainsi une collaboration efficace entre l’automatisation et l’expertise. Les résultats observés sont très encourageants. Non seulement le délai d’obtention des résultats ADN est drastiquement réduit, mais le taux d’erreur diminue également grâce à la standardisation apportée par l’algorithme.
L’IA ne remplace pas l’humain mais le complète
Une autre avancée prometteuse concerne l’amélioration du portrait-robot génétique à partir de l’ADN. Actuellement, cette technique permet d’estimer certaines caractéristiques physiques d’un individu (comme la couleur des yeux, des cheveux ou la pigmentation de la peau) à partir de son code génétique, mais elle reste limitée par la complexité des interactions génétiques et l’incertitude des prédictions. L’IA pourrait révolutionner cette approche en exploitant des modèles de deep learning* entraînés sur de vastes bases de données génétiques et phénotypiques, permettant ainsi d’affiner ces prédictions et de générer des portraits plus précis. Contrairement aux méthodes classiques, qui reposent sur des probabilités statistiques, un modèle d’IA pourrait analyser des millions de variantes génétiques en quelques secondes et identifier des corrélations subtiles que les approches traditionnelles ne détectent pas. Cette perspective ouvre la voie à une amélioration significative de la pertinence des portraits ADN, facilitant l’identification des suspects en l’absence d’autres indices exploitables. La plate-forme Forenseek a exploré les avancées actuelles dans ce domaine, mais l’IA n’a pas encore été pleinement exploitée pour surpasser les méthodes existantes [5]. Son intégration pourrait donc constituer une avancée majeure dans l’enquête criminelle.
Il est important de noter que dans tous ces exemples, l’IA ne remplace pas l’humain mais le complète. À l’IRCGN (Institut de Recherche Criminelle de la Gendarmerie Nationale) cité plus haut, si la majorité des profils ADN de routine et de bonne qualité peuvent être traités automatiquement, un contrôle qualité humain régulier subsiste : chaque semaine, un technicien revérifie aléatoirement des dossiers traités par l’IA, pour s’assurer qu’aucune dérive n’apparaît [3]. Cette collaboration homme-machine est la clé d’un déploiement réussi, car le savoir-faire de l’expert criminalistique reste indispensable pour valider et interpréter finement les résultats, notamment lorsqu’un cas est complexe.

Des algorithmes nourris aux données : comment l’IA « apprend » en forensique
Les performances impressionnantes de l’IA en criminalistique reposent sur une ressource cruciale : les données. Pour qu’un algorithme d’apprentissage automatique sache identifier une empreinte digitale ou interpréter un profil ADN, il doit préalablement être entraîné sur de nombreux exemples. Concrètement, nous lui fournissons des jeux de données représentatifs, comportant chacun des entrées (images, signaux, profils génétiques, etc.) associées à un résultat attendu (identité du bon suspect, composition exacte du profil ADN, etc.). En analysant ces milliers (voir millions) d’exemples, la machine ajuste ses paramètres internes afin de reproduire au mieux les décisions des experts humains. On parle d’apprentissage supervisé, car l’IA apprend à partir de cas que l’on connaît déjà. Par exemple, pour entraîner un modèle à reconnaître des profils ADN, nous utilisons des données issues de cas résolus où l’on sait quel était le résultat attendu.
La performance d’une IA dépend de la qualité des données qui l’entraînent.
Plus le volume de données d’entraînement est grand et varié, mieux l’IA pourra détecter des motifs robustes et fiables. Toutefois, toutes les données ne se valent pas. Il faut s’assurer qu’elles soient de bonne qualité (par exemple, des images bien annotées, des profils ADN sans erreur de saisie) et qu’elles couvrent une diversité de situations suffisante. Si on biaise le système en ne lui montrant qu’un éventail restreint de cas, ce dernier risque d’échouer face à un scénario un peu différent. En génétique, cela signifie par exemple d’inclure des profils d’origines ethniques variées, des niveaux de dégradation différents, des configurations de mélanges multiples, afin que l’algorithme apprenne à gérer toutes les sources de variations possibles.
La transparence dans la composition des données est un impératif. Des études ont montré que certaines bases de données forensiques sont démographiquement déséquilibrées : par exemple, la base américaine CODIS comporte une sur-représentation de profils d’individus afro-américains par rapport aux autres groupes [6]. Un modèle entraîné naïvement sur ces données pourrait hériter de biais systématiques et produire des résultats moins fiables ou moins justes pour des populations sous-représentées. Il est donc indispensable de contrôler les biais dans les données d’apprentissage et, si nécessaire, de les corriger (par échantillonnage équilibré, augmentation de données minoritaires, etc.) afin d’obtenir un apprentissage équitable.
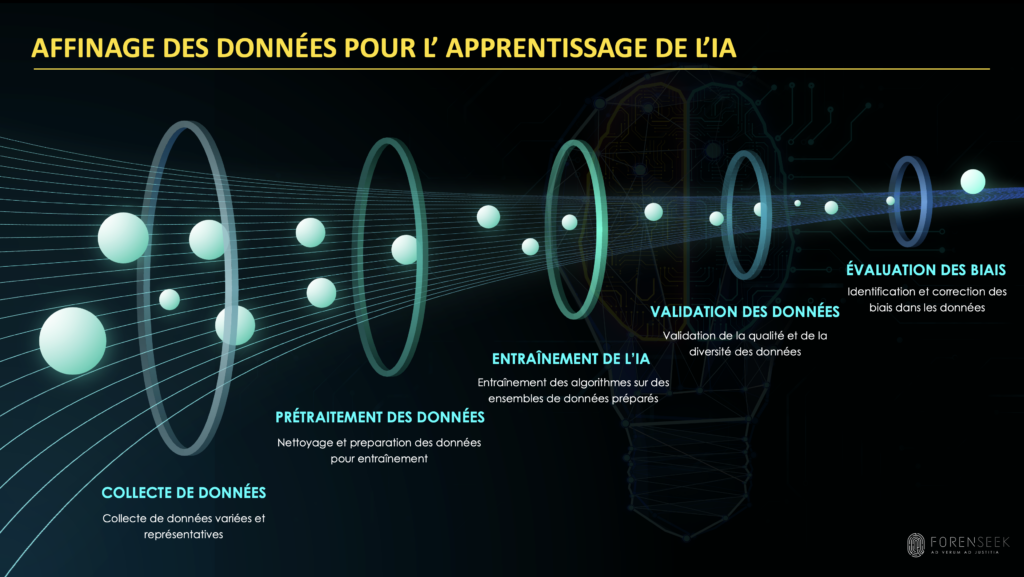
Techniquement, l’entraînement d’une IA passe par des étapes rigoureuses de validation croisée et de mesure de performance. On divise généralement les données en trois ensembles : un pour l’apprentissage, un pour la validation pendant le développement (pour ajuster les paramètres) et un jeu de test final pour évaluer le modèle de façon objective. Des métriques quantitatives comme la précision, le rappel (sensibilité) ou les courbes d’erreur permettent de quantifier la fiabilité de l’algorithme sur des données qu’il n’a jamais vues [6]. On peut ainsi vérifier, par exemple, que l’IA identifie correctement une grande majorité des auteurs à partir de traces, tout en maintenant un faible taux de faux positifs. De plus en plus, nous intégrons également des critères de justice et d’éthique dans ces évaluations : nous examinerons si la performance reste constante quel que soit le groupe démographique ou la condition du test (genre, âge, etc.), afin de s’assurer qu’aucun biais inacceptable ne subsiste [6]. Enfin, le respect des contraintes juridiques (telles que le RGPD en Europe, qui encadre l’utilisation des données personnelles) doit être intégré dès la phase de conception du système [6]. Cela peut impliquer d’anonymiser les données, de limiter certaines informations sensibles ou de prévoir des procédures en cas de détection d’un biais éthique.
En définitive, la performance d’une IA dépend de la qualité des données qui l’entraînent. Dans le domaine forensique, cela signifie que les algorithmes « apprennent » à partir de l’expertise humaine accumulée. Chaque décision algorithmique porte en filigrane l’expérience de centaines d’experts qui ont fourni des exemples ou ajusté les paramètres. C’est à la fois une force (nous capitalisons sur une base de connaissance énorme) et une responsabilité : celle de bien sélectionner, préparer et contrôler les données qui serviront à nourrir l’intelligence artificielle.
Défis techniques et opérationnels pour intégrer l’IA en police scientifique
Si l’IA fait miroiter des gains substantiels, son intégration concrète sur le terrain forensique s’accompagne de nombreux défis. Il ne suffit pas d’entraîner un modèle en laboratoire : encore faut-il pouvoir l’utiliser dans le cadre contraint d’une enquête judiciaire, avec toutes les exigences de fiabilité que cela implique. Parmi les principaux défis techniques et organisationnels, on peut citer :
- Accès aux données et infrastructures : paradoxalement, alors que l’IA a besoin de beaucoup de données pour apprendre, il peut être difficile de rassembler ces données en quantité suffisante dans le domaine forensique visé. Les profils ADN, par exemple, sont des données personnelles hautement sensibles, protégées par la loi et cloisonnées dans des bases sécurisées. Obtenir des jeux de données assez volumineux pour entraîner un algorithme peut nécessiter des coopérations complexes entre services, ou la génération de données synthétiques pour combler les manques. De plus, les outils informatiques doivent être adaptés pour traiter en temps raisonnable des masses de données – ce qui implique des investissements en matériel (serveurs, GPU2 pour le deep learning3) et en logiciels spécialisés. Certaines initiatives nationales commencent à voir le jour pour mutualiser des données forensiques de façon sécurisée, mais cela reste un chantier en cours.
- Qualité des annotations et biais : l’apprentissage d’une IA dépend de la qualité de l’annotation des données d’entraînement. Dans bien des domaines forensiques, établir le « vrai » n’est pas trivial. Par exemple, pour entraîner un algorithme à reconnaître un visage sur une vidéo de surveillance, il faut que chaque visage soit correctement identifié par un humain au préalable – ce qui peut être ardu si l’image est floue ou partielle. De même, étiqueter des jeux de traces de semelles, de fibres ou des empreintes demandent un travail méticuleux d’experts, avec parfois une part de subjectivité. Si les données d’apprentissage comportent des erreurs d’annotation ou des biais historiques, l’IA les reproduira [6]. Un biais classique est lié à la représentativité démographique mentionnée plus haut, mais il peut y en avoir d’autres. Par exemple, si nous entraînons un modèle de détection d’armes principalement sur des images d’armes en intérieur, il sera moins performant pour détecter une arme en extérieur, sous la pluie, etc. La qualité et la diversité des données annotées sont donc un enjeu technique majeur. Cela implique d’établir des protocoles rigoureux de collecte et d’annotation (idéalement standardisés au niveau international), ainsi qu’un contrôle continu pour détecter les dérives du modèle (surapprentissage sur certains cas, perte de performance dans le temps, etc.). Cette validation repose sur des études expérimentales comparant les performances de l’IA aux experts humains. Toutefois, la complexité des procédures d’homologation et d’acquisition freine parfois l’adoption, retardant de plusieurs années la mise en service de nouveaux outils en criminalistique.

- Compréhension et acceptation par les acteurs judiciaires : introduire de l’intelligence artificielle dans le processus judiciaire soulève inévitablement la question de la confiance. Un enquêteur ou un technicien de laboratoire, formé aux méthodes classiques, doit apprendre à utiliser et à interpréter les résultats fournis par l’IA. Cela nécessite des formations et une acculturation progressive pour que l’outil devienne un allié et non une « boîte noire incomprise ». Plus largement, les magistrats, avocats et jurés qui auront à discuter ces preuves doivent aussi en saisir les principes. Or, expliquer le fonctionnement interne d’un réseau de neurones ou la signification statistique d’un score de similarité n’est pas aisé. Nous observons parfois une incompréhension ou une méfiance de la part de certains acteurs judiciaires face à ces méthodes algorithmiques [6]. Si un juge ne comprend pas comment une conclusion a été obtenue, il pourrait être enclin à la rejeter ou à lui accorder moins de poids, par prudence. De même, un avocat de la défense cherchera légitimement à scruter les failles d’un outil qu’il ne connaît pas, ce qui peut donner lieu à des débats judiciaires autour de la validité de l’IA. Un défi conséquent est donc de rendre l’IA explicable (concept de « XAI » pour eXplainable AI), ou du moins d’en présenter les résultats dans un format compréhensible et pédagogiquement acceptable par un tribunal. Sans cela, l’intégration de l’IA risque de se heurter à un refus ou à des controverses lors des procès, limitant son apport pratique.
- Cadre réglementaire et protection des données : enfin, les sciences forensiques évoluent dans un cadre légal strict, notamment en ce qui concerne les données personnelles (profil ADN, données biométriques, etc…) et la procédure pénale. L’utilisation d’une IA doit respecter ces régulations. En France, la CNIL (Commission Nationale de l’Informatique et des Libertés) veille au grain et peut imposer des restrictions si un traitement algorithmique porte atteinte à la vie privée. Par exemple, entraîner une IA sur des profils ADN nominatifs sans base légale serait impensable. Il faut souvent innover tout en restant dans les clous juridiques, ce qui impose des contraintes dès la conception des projets. Par ailleurs, le secret industriel autour de certains algorithmes pose un problème dans le contexte judiciaire : si un éditeur refuse de divulguer le fonctionnement interne de son logiciel pour des raisons de propriété intellectuelle, comment la défense ou le juge peuvent-ils s’assurer de sa fiabilité ? Des cas récents ont montré des accusés condamnés sur la foi de logiciels propriétaires (par exemple d’analyse ADN) sans que la défense n’ait pu examiner le code source utilisé [7]. Ces situations soulèvent un enjeu de transparence et de droits de la défense. Aux États-Unis, une proposition de loi intitulée « Justice in Forensic Algorithms Act » entend justement faire en sorte que le secret commercial ne puisse pas empêcher l’examen par des experts des algorithmes employés en criminalistique, afin de garantir l’équité des procès. Cela illustre bien la nécessité d’adapter le cadre réglementaire à ces nouvelles technologies.
Le manque de coopération ralentit la mise au point d’outils performants et limite leur adoption sur le terrain.
- Un autre obstacle, plus structurel, réside dans la difficulté d’intégrer des profils hybrides aux institutions forensiques tout du moins en France. Aujourd’hui, les concours et les recrutements restent souvent cloisonnés entre différentes spécialités, limitant l’émergence d’experts possédant une double compétence. Par exemple, dans la police scientifique, le concours de technicien ou d’ingénieur de police scientifique est accessible via des spécialités distinctes, comme la biologie ou l’informatique, mais ne permet pas de valoriser une expertise combinée aux deux. Cette rigidité institutionnelle freine l’intégration de professionnels capables de faire le lien entre les domaines et d’exploiter pleinement le potentiel de l’IA en criminalistique. Pourtant, les avancées technologiques actuelles montrent que l’analyse des traces biologiques repose de plus en plus sur des outils numériques avancés. Face à cette évolution, une plus grande souplesse dans le recrutement et la formation des experts forensiques sera nécessaire pour répondre aux défis de demain.
L’IA en criminalistique ne doit pas être un enjeu de compétition ou de prestige entre laboratoires, mais un outil mis au service de la justice et de la vérité, au bénéfice des enquêteurs et des victimes.
- Un autre frein majeur à l’innovation en criminalistique est le cloisonnement des efforts entre les différents acteurs du domaine qui travaillent en parallèle sur des problématiques identiques, sans mutualiser leurs avancées. Ce manque de coopération ralentit la mise au point d’outils performants et limite leur adoption sur le terrain. Pourtant, en partageant nos ressources – qu’il s’agisse de bases de données, de méthodologies ou d’algorithmes – nous pourrions accélérer la mise en production des solutions IA et garantir une amélioration continue fondée sur l’expertise de chacun. Mon expérience à travers les différents laboratoires français (Le Laboratoire de Police Scientifique de Lyon (Service National de Police Scientifique SNPS), L’Institut de Recherche Criminelle de la Gendarmerie Nationale (IRCGN) et maintenant l’Institut Génétique Nantes Atlantique IGNA) me permet de mesurer combien cette fragmentation freine les progrès, alors que nous poursuivons un même objectif : améliorer la résolution des enquêtes. C’est pourquoi il est essentiel de promouvoir le développement en open source lorsque cela est possible et de créer des plateformes de collaboration entre les entités publiques et judiciaires. L’IA en criminalistique ne doit pas être un enjeu de compétition ou de prestige entre laboratoires, mais un outil mis au service de la justice et de la vérité, au bénéfice des enquêteurs et des victimes.

Enjeux éthiques et légaux : innover sans renoncer aux garanties
Les défis évoqués ci-dessus ont tous une dimension technique, mais ils s’entremêlent à des questions éthiques et juridiques fondamentales. D’un point de vue éthique, la priorité absolue est de ne pas causer d’injustice par l’usage de l’IA. Il faut à tout prix éviter qu’un algorithme mal conçu n’entraîne l’inculpation injustifiée d’une personne ou, à l’inverse, le relâchement d’un coupable. Cela passe par la maîtrise des biais (pour ne pas discriminer certains groupes), par la transparence (pour que chaque partie au procès puisse comprendre et contester la preuve algorithmique) et par la responsabilisation des décisions. En effet, qui est responsable si une IA se trompe ? L’expert qui l’a utilisée à tort, le concepteur du logiciel, ou personne car « la machine a fait une erreur » ? Ce flou n’est pas acceptable en justice : il importe de toujours garder l’expertise humaine dans la boucle, de façon qu’une décision finale – incriminer ou disculper – repose sur une évaluation humaine éclairée par l’IA, et non sur le verdict opaque d’un automate.
Sur le plan légal, le paysage est en train d’évoluer pour encadrer l’utilisation de l’IA. L’Union européenne, notamment, finalise un Règlement sur l’IA (AI Act) qui sera la première législation au monde à définir un cadre pour le développement, la commercialisation et l’utilisation des systèmes d’intelligence artificielle [8]. Son objectif est de minimiser les risques pour la sécurité et les droits fondamentaux des personnes, en imposant des obligations en fonction du niveau de risque de l’application (et nul doute que les usages en matière pénale seront classés parmi les plus sensibles). En France, la CNIL a publié des recommandations soulignant qu’il est possible de concilier innovation et respect des droits des personnes lors du développement de solutions d’IA [9]. Cela passe par exemple par le respect du RGPD, la limitation des finalités (nous n’entraînons un modèle qu’à des fins légitimes et clairement définies), la proportionnalité des données collectées, et l’évaluation d’impact préalable pour tout système algorithmique susceptible d’affecter significativement les individus. Ces garde-fous visent à ce que l’enthousiasme pour l’IA ne se fasse pas au détriment des principes fondamentaux de la justice et de la vie privée.
Encourager l’innovation tout en exigeant une validation scientifique solide et une transparence sur les méthodes
Un équilibre délicat doit donc être trouvé entre innovation technologique et cadre réglementaire. D’un côté, brider excessivement l’expérimentation et l’adoption de l’IA en criminalistique pourrait priver les enquêteurs d’outils potentiellement salvateurs dans la résolution d’enquêtes complexes. De l’autre, laisser le champ libre sans règles ni contrôle serait prendre le risque d’erreurs judiciaires ou d’atteintes aux droits. La solution réside sans doute dans une approche mesurée : encourager l’innovation tout en exigeant une validation scientifique solide et une transparence sur les méthodes. Des comités d’éthique et des experts indépendants peuvent être associés pour auditer les algorithmes, vérifier qu’ils respectent bien les normes et qu’ils ne reproduisent pas de biais problématiques. En outre, il convient d’informer et de former les professionnels du droit à ces nouvelles technologies, afin qu’ils soient en mesure d’en discuter avec pertinence lors des procès. Un juge formé aux concepts de base de l’IA sera plus à même de comprendre la valeur probante (et les limites) d’une preuve issue d’un algorithme.
Conclusion : L’avenir de la criminalistique à l’ère de l’IA
L’intelligence artificielle est en passe de transformer en profondeur la criminalistique, apportant aux enquêteurs des outils d’analyse plus rapides, plus précis et capables d’exploiter des volumes de données autrefois inaccessibles. Qu’il s’agisse de passer au crible des giga-octets d’informations numériques, de comparer des traces latentes avec une fiabilité accrue, ou de démêler des profils ADN complexes en quelques minutes, l’IA ouvre de nouvelles perspectives pour résoudre les enquêtes plus efficacement.
Mais cette avancée technologique s’accompagne de défis cruciaux. Techniques d’apprentissage, qualité des bases de données, biais algorithmiques, transparence des décisions, cadre réglementaire : autant d’enjeux qui détermineront si l’IA peut réellement renforcer la justice sans la fragiliser. À l’heure où la confiance du public dans les outils numériques est plus que jamais mise à l’épreuve, il est impératif d’intégrer ces innovations avec rigueur et responsabilité.
L’avenir de l’IA en criminalistique ne sera pas un face-à-face entre la machine et l’homme, mais un travail de collaboration où l’expertise humaine restera centrale. La technologie pourra aider à voir plus vite, plus loin, mais l’interprétation, le discernement et la prise de décision resteront entre les mains des experts forensiques et du monde judiciaire. Dès lors, la vraie question n’est peut-être pas jusqu’où l’IA peut aller en criminalistique, mais comment saurons-nous l’encadrer afin qu’elle puisse garantir une justice éthique et équitable. Serons-nous capables d’exploiter sa puissance tout en préservant les fondements mêmes du procès équitable et du droit à la défense ?
La révolution est en marche. Il nous appartient désormais d’en faire un progrès et non une dérive.
Bibliographie
[1] : Océane DUBOUST. L’IA peut-elle aider la police scientifique à trouver des similitudes dans les empreintes digitales ? Euronews, 12/01/2024 [vue le 15/03/2025] https://fr.euronews.com/next/2024/01/12/lia-peut-elle-aider-la-police-scientifique-a-trouver-des-similitudes-dans-les-empreintes-d#:~:text=,il
[2] : International Journal of Multidisciplinary Research and Publications. The Role of Artificial Intelligence in Forensic Science: Transforming Investigations through Technology. Muhammad Arjamand et al. Volume 7, Issue 5, pp. 67-70, 2024. Disponible sur : http://ijmrap.com/ [vue le 15/03/2025]
[3] : Gendarmerie Nationale. Kit universel, puce RFID, IA : le PJGN à la pointe de la technologie sur l’ADN. Mis à jour le 22/01/2025 et disponible sur : https://www.gendarmerie.interieur.gouv.fr/pjgn/recherche-et-innovation/kit-universel-puce-rfid-ia-le-pjgn-a-la-pointe-de-la-technologie-sur-l-adn [vue le 15/03/2025]
[4] : Michelle TAYLOR. EXCLUSIVE: Brand New Deterministic Software Can Deconvolute a DNA Mixture in Seconds. Forensic Magazine, 29/03/022. Disponible sur : https://www.forensicmag.com [vue le 15/03/2025]
[5] : Sébastien AGUILAR. L’ADN à l’origine des portraits-robot ! Forenseek, 05/01/2023. Disponible sur : https://www.forenseek.fr/adn-a-l-origine-des-portraits-robot/ [vue le 15/03/2025]
[6] : Max M. Houck, Ph.D. CSI/AI: The Potential for Artificial Intelligence in Forensic Science. iShine News, 29/10/2024. Disponible sur : https://www.ishinews.com/csi-ai-the-potential-for-artificial-intelligence-in-forensic-science/ [vue le 15/03/2025]
[7] : Mark Takano. Black box algorithms’ use in criminal justice system tackled by bill reintroduced by reps. Takano and evans. Takano House, 15/02/2024. Disponible sur : https://takano.house.gov/newsroom/press-releases/black-box-algorithms-use-in-criminal-justice-system-tackled-by-bill-reintroduced-by-reps-takano-and-evans [vue le 15/03/2025]
[8] : Mon Expert RGPD. Artificial Intelligence Act : La CNIL répond aux premières questions. Disponible sur : https://monexpertrgpd.com [vue le 15/03/2025]
[9] : CNIL. Les fiches pratiques IA. Disponible sur : https://www.cnil.fr [vue le 15/03/2025]
Définitions :
- Le Machine Learning (apprentissage automatique) est une branche de l’intelligence artificielle qui permet aux ordinateurs d’apprendre à partir de données sans être explicitement programmés. Il repose sur des algorithmes capables de détecter des motifs, de faire des prédictions et d’améliorer leurs performances avec l’expérience. ↩︎
- Un GPU (Graphics Processing Unit) est un processeur spécialisé conçu pour exécuter des calculs massivement parallèles, principalement utilisés pour le rendu graphique. Contrairement aux CPU (processeurs centraux) qui exécutent un nombre limité de tâches séquentielles avec des cœurs optimisés pour la polyvalence, les GPU possèdent des milliers de cœurs optimisés pour effectuer des opérations simultanées sur de grandes quantités de données. ↩︎
- Le Deep Learning (apprentissage profond) est une branche du Machine Learning qui utilise des réseaux de neurones artificiels composés de plusieurs couches pour modéliser des représentations complexes des données. Inspiré du fonctionnement du cerveau humain, il permet aux systèmes d’IA d’apprendre à partir de grandes quantités de données et d’améliorer leurs performances avec l’expérience. Le Deep Learning est particulièrement efficace pour le traitement des images, de la parole, du texte et des signaux complexes, avec des applications en vision par ordinateur, reconnaissance vocale, médecine légale et cybersécurité. ↩︎